
ChatGPT i druge aplikacije koje se oslanjaju na velike jezične modele (LLM) sve se više koriste i privlače veliku pažnju medija. Tim prostorom dominira nekoliko velikih, dobro financiranih tehnoloških tvrtki jer je prethodna obuka (predtrening) ovih modela iznimno skupo, minimalno 10 milijuna dolara, a često i deset puta više. Kako bi to promijenili, istraživači Sveučilište Stanford odlučio poboljšati trenutne metode optimizacije LLM-a. Rezultat je novi pristup tzv Sofija koji prepolovljuje vrijeme prije treninga.
Procjena zakrivljenosti
LLM modeli imaju milijune ili čak milijarde parametara, a jedan od njihovih svojstava je njihova zakrivljenost. Program za optimizaciju koji može procijeniti tu zakrivljenost, mogao bi i predobučavanje učiniti učinkovitijim. Problem je u tome što je procijenjena zakrivljenost postojećim metodama izuzetno teška i skupa. To je i jedan od razloga zašto trenutno najsuvremeniji pristupi optimizaciji predobučavanja, poput Adama i njegovih izvođača, odustaju od procjene zakrivljenosti.
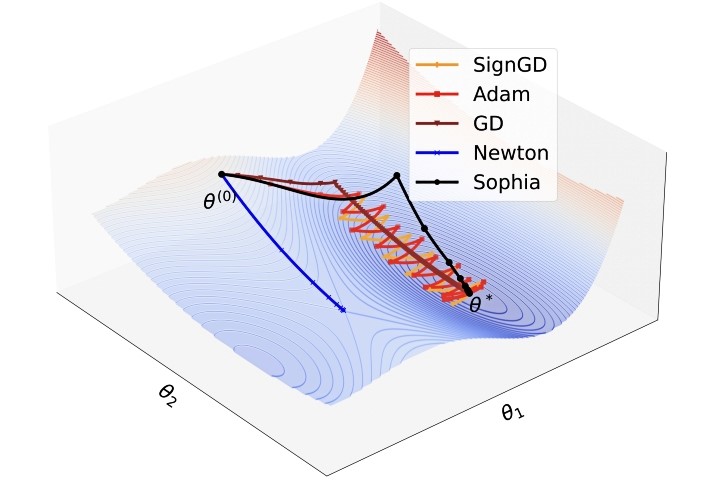
Umjesto zakrivljenosti pri svakom koraku optimizacije, istraživači sa Stanforda odlučili su učiniti proces procjene učinkovitijim smanjenjem broja ažuriranja i dizajnirali su Sophiu da procjenjuje zakrivljenost parametra svakih 10 koraka. Eksperimenti su pokazali da je to bio dobar potez. Baš kao isječak kojim ste riješili problem netočne procjene krivice.
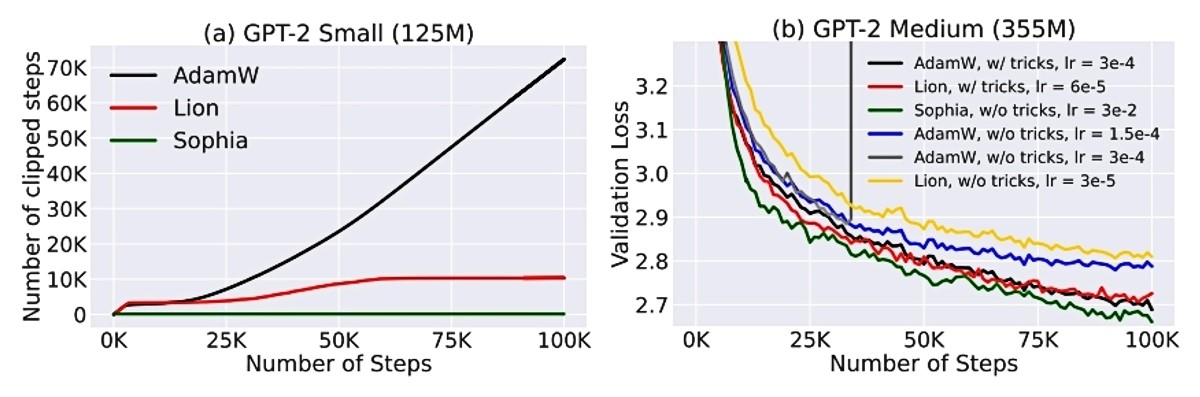
U konačnici, ova kombinacija procjene okrivljenosti i isječak omogućila je optimizaciju u upola manjem broju koraka i upola kraćem vremenu nego što je to bilo potrebno Adamu.
Sophijin izbor
“Sofijina prilagodljivost razlikuje se od Adama kojemu je teže rukovati parametrima s heterogenim zakrivljenjima jer ih se ne može predvidjeti”, objašnjavaju istraživači koji su prvi značajan napredak u predobučavanju jezičnog modela postigli punih devet godina nakon standarda koji je postavio Adam.
Istraživači se nadaju da će korištenjem Sophije razviti veći LLM te da će se primijeniti i na drugom području strojnog učenja kao što su modeli računalnog vida ili multimodalni modeli.
Više o temiIzvor:Bug.hr





{kind=link}